分词的概念
分词就是将连续的字序列按照一定的规范重新组合成词序列的过程
目前的分词方法归纳起来有3类:
第一类是基于语法和规则的分词法。
在分词的同时进行句法、语义分析, 利用句法信息和语义信息来进行词性标注, 以解决分词歧义现象。现有的语法知识、句法规则十分笼统、复杂, 基于语法和规则的分词法所能达到的精确度远远还不能令人满意。第二类是机械式分词法(即基于词典)。
将文档中的字符串与词典中的词条进行逐一匹配, 如果词典中找到某个字符串, 则匹配成功, 可以切分, 否则不予切分。优点:实现简单, 实用性强; 缺点:词典的完备性不能得到保证。第三类是基于统计的方法。
根据字符串在语料库中出现的统计频率来决定其是否构成词。词是字的组合, 相邻的字同时出现的次数越多, 就越有可能构成一个词。
最大匹配是指以词典为依据,取词典中最长单词为第一个次取字数量的扫描串,在词典中进行扫描,这是基于词典分词的方法
正向最大匹配法
从左到右将待分词文本中的几个连续字符与词表匹配,如果匹配上,则切分出一个词。
注意:要做到最大匹配,并不是第一次匹配到就可以切分的 。
最大匹配出的词必须保证下一个扫描不是词表中的词或词的前缀才可以结束。
逆向最大匹配法
逆向即从后往前取词,其他逻辑和正向相同。
(1) 将文章分成句子(通过标点符号来实现);
(2) 循环的读入每一个句子S,设句子中的字数为n;
(3) 设置一个最大词长度,就是我们要截取的词的最大长度max;
(4) 从句子中取n-max到n的字符串subword,去字典中查找是否有这个词。如果有就走(5),没有就走(6);
(5) 记住subword,从n-max付值给n,继续执行(4),直到n=0。
(6) 将max-1,再执行(4)。双向最大匹配法:
正向最大匹配法和逆向最大匹配法,都有其局限性。
双向最大匹配法,即两种算法都切一遍,然后根据大颗粒度词越多越好,非词典词和单字词越少越好的原则,选取其中一种分词结果输出。
词、字符频率统计
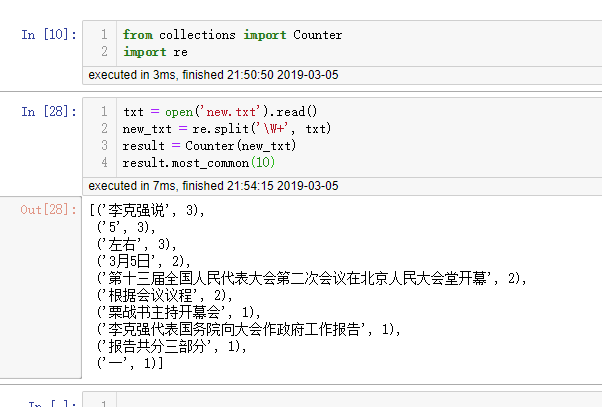
语言模型
一个语言模型通常构建为字符串s的概率分布p(s),这里的p(s)实际上反映的是s作为一个句子出现的概率。这里的概率指的是组成字符串的这个组合,在训练语料中出现的似然,与句子是否合乎语法无关。
语言模型中unigram、bigram、trigram的概念
n-gram模型也称为$n-1$阶马尔科夫模型,它有一个有限历史假设:第$N$个词的出现只与前面$N-1$个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。
当$n$取1、2、3时,n-gram模型分别称为unigram、bigram和trigram语言模型。
- unigrams
一元分词,把句子从头到尾分成一个一个的汉字 - bigrams
二元分词,把句子从头到尾每两个字组成一个词语 - trigrams
三元分词,把句子从头到尾每三个字组成一个词语
最常用的是bigram,其次是unigram和trigram,$n$取$≥4$的情况较少。
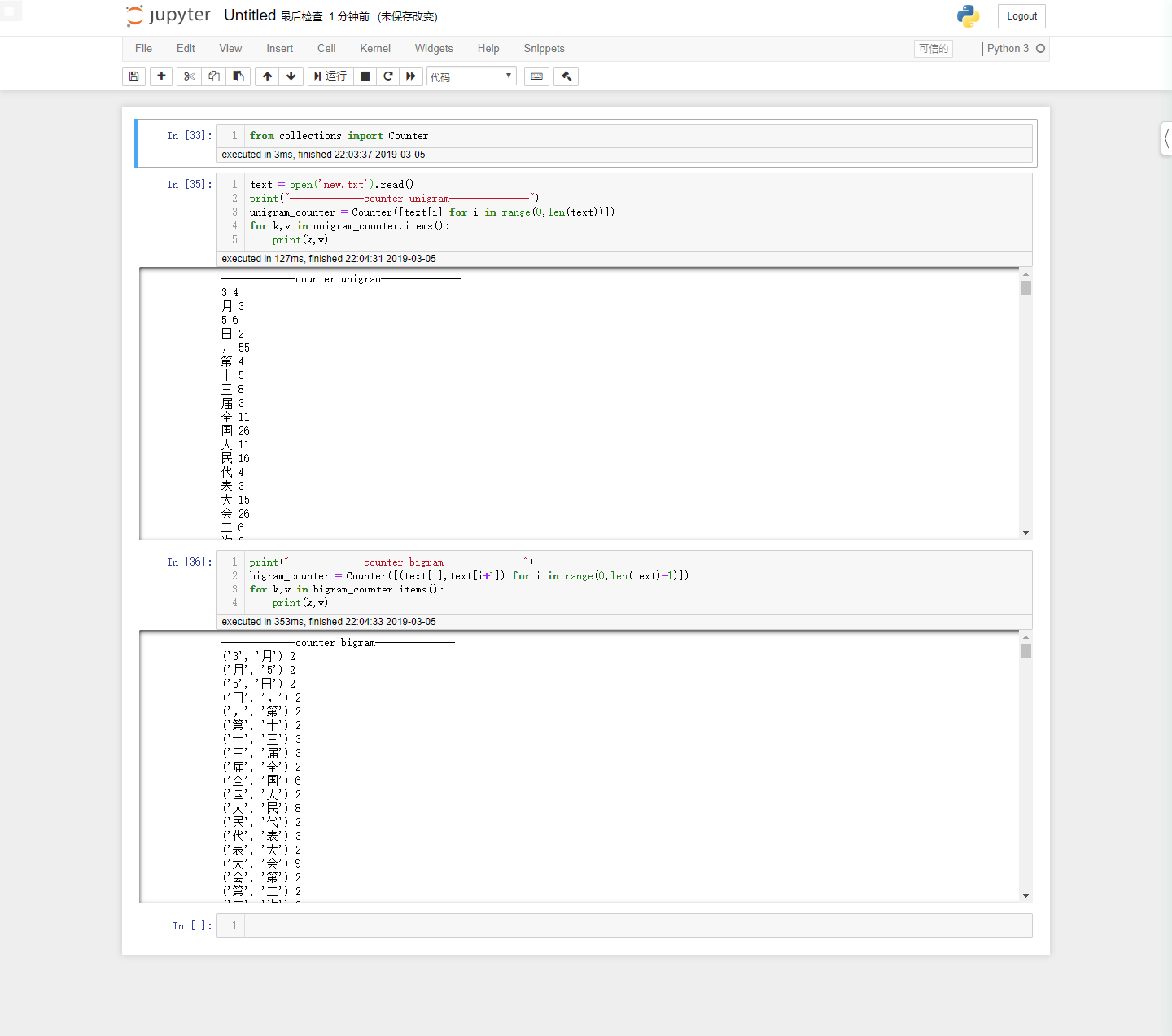
unigram、bigram频率统计
文本矩阵化:要求采用词袋模型且是词级别的矩阵化
步骤有:
分词(可采用结巴分词来进行分词操作,其他库也可以);去停用词;构造词表。
每篇文档的向量化。

