基本的Attention原理
深度学习里的 Attention model 其实模拟的是人脑的注意力模型。举例来说,当我们观赏一幅画时,虽然我们可以看到整幅画的全貌,但是在我们深入仔细地观察时,其实眼睛聚焦的就只有很小的一块,这个时候人的大脑主要关注在这一小块图案上,也就是说这个时候人脑对整幅图的关注并不是均衡的,是有一定的权重区分的。这就是深度学习里的Attention Model的核心思想。
注意力机制在使用encoder-decoder结构进行神经机器翻译(NMT)的过程中被提出来,并且迅速的被应用到相似的任务上,比如根据图片生成一段描述性语句、梗概一段文字的内容。从一个高的层次看,允许decoder从多个上下文向量(context vector)中选取需要的部分,使得Encoder从只能将上下文信息压缩到固定长度的向量中这个束缚中解放出来,进而可以表示更多的信息。
目前,注意力机制在深度学习模型中十分常见,而不仅限于encoder-decoder层次结构中。值得一提的是,注意力机制可以仅应用在encoder上,以解决诸如文本分类或者表示学习的任务上。这种注意力机制的应用被称为自聚焦或者内部聚焦机制。
下面我们从神经机器学习(NMT)使用的encoder-decoder结构开始介绍聚焦机制,之后我们会介绍自聚焦机制。
Encoder-decoder简介
从一个抽象的层次上看,encoder将输入压缩成一个高维的上下文向量,而decoder则可以从这个上下文向量中产生输出。

在神经机器翻译(NMT)中,输入和输出都是单词的序列,分别表示为 $x=(x_1,\dots ,x_{Tx}$ 和 $y=(y_1,\dots ,y_{Ty}$,$x$ 和 $y$ 称为源句(source sentence)和目标句(target sentence)。当输入和输出都是句子序列时,这样的 encoder-decoder 结构也被成为是 seq2seq 模型。由于encoder-decoder结构处处可微的性质,模型中的参数集 $\theta$ 的最优解等效于在整个语料库上计算似然函数的最大值(MLE),这种训练的方式称为端到端(end-to-end)。
这里我们想要最大化的函数是预测正确单词的概率的对数。
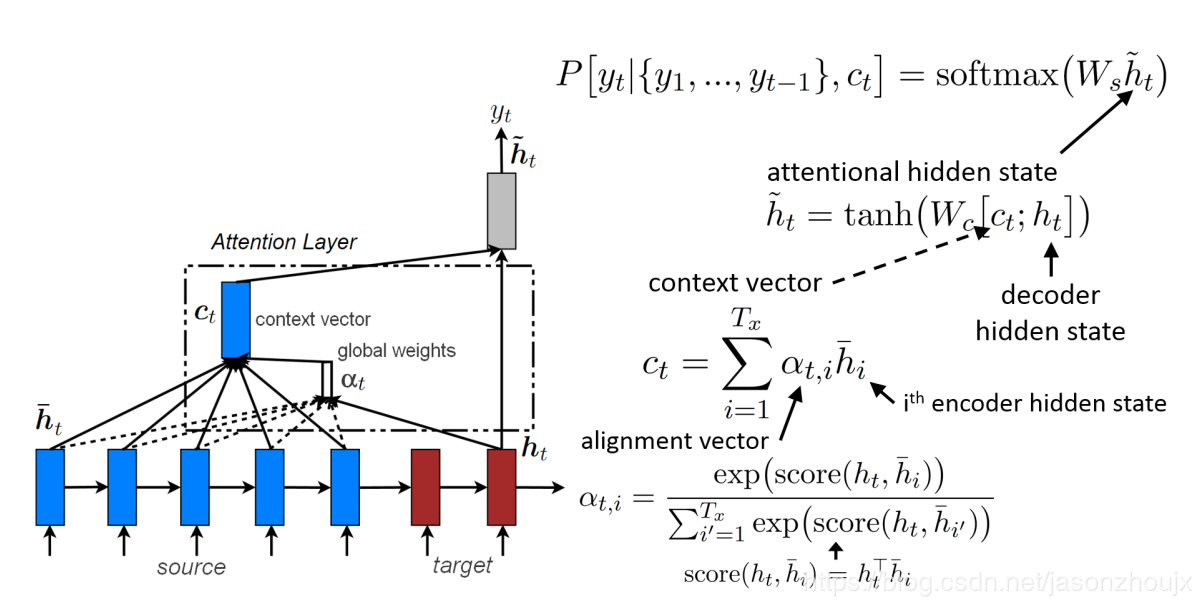
Global attention
上下文向量(context vector) $c_t$ 通过计算源句子(source sentence)的所有注释(annotation),也即 encoder 的所有隐藏状态(hidden state)的加权和得到。一共有 $T_x$ 个注释(source sentence的长度),每一个注释都是大小为 encoder 隐藏层单元数的向量,$c_t$ 和所有注释的形状相同。分配向量(alignment vector)$\alpha_t$ 的形状和source sentence的长度 $T_x$ 相同,是一个变量。
分配向量的计算过程分为两步,首先分别计算decoder当前step的隐藏状态 $h_t$ 和encoder的所有隐藏状态 $\overline h_i$ 的alignment运算的结果(alignment运算下面会介绍),再应用softmax函数计算 $exp(score(h_t,\overline h_i))$ 在所有 $\sum_{i’}^{T_x}exp(score(h_t,\overline h_{i’}))$ 中的比重。
换句话说,$c_t$ 可以看作是所有encoder的隐藏状态的分布律(每个状态的概率处于 $[0,1]$ 并且和为 $1$),进而预示source sentence中对预测下一个单词最优帮助的词汇。$score()$ 函数理论上可以是任意的比较函数。Luong在他的论文中使用点积(dot product)($score(h_t,\overline h_i)=h_t ^{\top}\overline h_i$),一个更加通用的方程是在点积基础上增加一个由全连接神经网络层训练的参数矩阵 $W_\alpha$,方程表示为 $score(h_t,\overline h_i)=h_t^TW_\alpha\overline h_i$,实验发现dot product在global attention中表现更好,而general方程在local attention中表现更好。
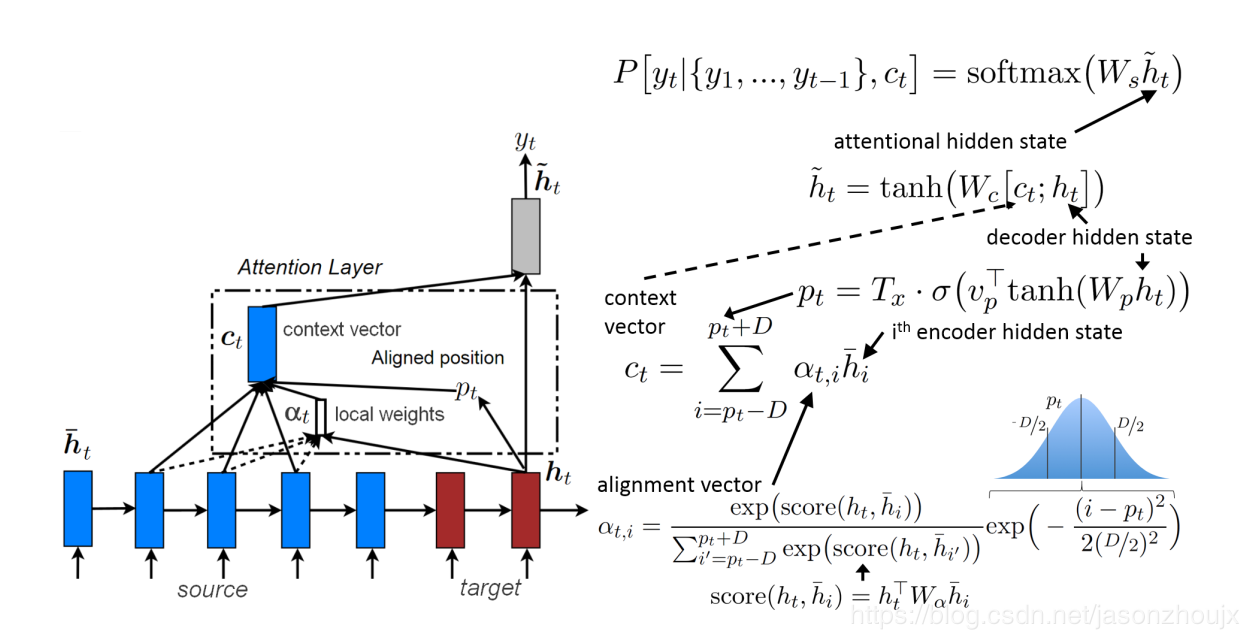
Local attention
每一次生成目标单词(target word)都分析source sentence中所有单词的做法代价太高,也许也是没有必要的。为了缓解这个问题,Luong论文中建议只集中关注一个固定大小 $2D+1$ 窗口中的source sentence 的注释(annotation),即只关注最能帮助预测下一个词汇的source sentence中某个词汇前后step的隐藏状态(hidden state):
其中,$D$ 由用户自定义,而窗口中心即聚焦的annotation $p_t$ 可以也设为 $t$ 或者基于保存了之前target words $(y_1, …y_{t-1})$ 信息的decoder隐藏状态的 $h_t$ 决定:$p_t = T_x · \sigma(v_p ^{\top} tanh(W_p h_t))$,$T_x$ 表示source sentence 的长度,$\sigma$ 表示sigmoid函数,$v_p$ 和 $W_p$ 是可训练的参数矩阵。分配矩阵(alignment weights)的计算过程和global attention中的相似,仅仅是增加了一项均值为 $p_t$ ,标准差为 $D/2$ 的标准正太分布乘积项:
注意 $p_t \in \mathbb{R} \cap [0, T_x]$ and $i \in \mathbb{R} \cap [p_t-D, p_t+D]$。添加的高斯分布项使得alignment权重随着 $i$ 在窗口中远离中心 $p_t$ 移动逐渐降低,也就是说对于给予靠近 $p_t$ 的annotation更多的影响力。另外和global attention不同的是 $\alpha _t$ 的大小被固定为 $2D-1$,只有处于窗口范围内的annotation才对输出有影响。local attention可以看成是alignment权重与一个截断高斯分布相乘后的global attention(窗口外的annotation取值为 $0$)。local attention的示意图如下所示:
self-attention
现在我们将encoder简单设置为单独的RNN处理长度为 $T$ 的句子 $(x_1, x_2, \dots, x_T)$。RNN将输出映射成annotation $(h_1, \dots , h_T)$。正如将attention机制引入到encoder-decoder结构中一样,不同于只关注当前的隐藏状态 $h_t$,将其作为整个句子的综合概括会失去许多信息,self attention不同的机制也能够将所有的annotation纳入学习的范围。
如下面公式所示,annotation $h_t$ 先被传输到一个全连接层,得到的输出 $u_t$ 被用于和一个可训练的用来表示上下文信息的参数矩阵 $u$(随机初始化)进行比较以得到annotation的分配系数(alignment coefficient),随后用softmax进行归一化。最后得到的聚焦化的向量 $s$ 是所有annotation的加权和。
score函数理论上可以是任意的比较函数。一个简单的得分函数是 $score(u_t, u) = u_t^ \top u$。
上面提及的上下文向量(context vector)和seq2seq模型的中context vector毫无联系!在seq2seq模型中,context vector $c_t$ 是encoder所有隐藏状态的加权和 $\sum _{i=1} ^{T_x} \alpha _{t,i} {\overline h}_i$,然后 $c_t$ 和decoder的隐藏状态 $h_t$ 共同用于计算聚焦化的隐藏状态 $\widetilde h = tanh(W_c [c_t;h_t])$。self attention中的上下文向量只是用来代替decoder的隐藏状态用于计算 $score()$,实际上self attention模型中并没有decoder模块。所以,self attention中的分配系数矩阵指示了上下文中各个单词之间的关联,而seq2seq模型中的上下文向量 $\alpha _t$ 代表的是source sentence中各词和即将生成的target词汇之间的关联。
下面图片展示了一个实际应用self attention的层次模型,其中self attention在两个层次起作用:单词层次和句子层次。这样做的理由有两个:如何自然语言的层次结构,词汇组成语句,语句组成文本;第二,这样使得模型可以学习到句子中需要重点关注的词和文本中需要重点关注的句子。由于各个sentence的attentional coefficient不同,各个句子下的各单词的attentional coefficients可以是不同的,这使得一个句子中某个单词的十分重要,到到了另一个句子中这个单词就变的不那么重要了。
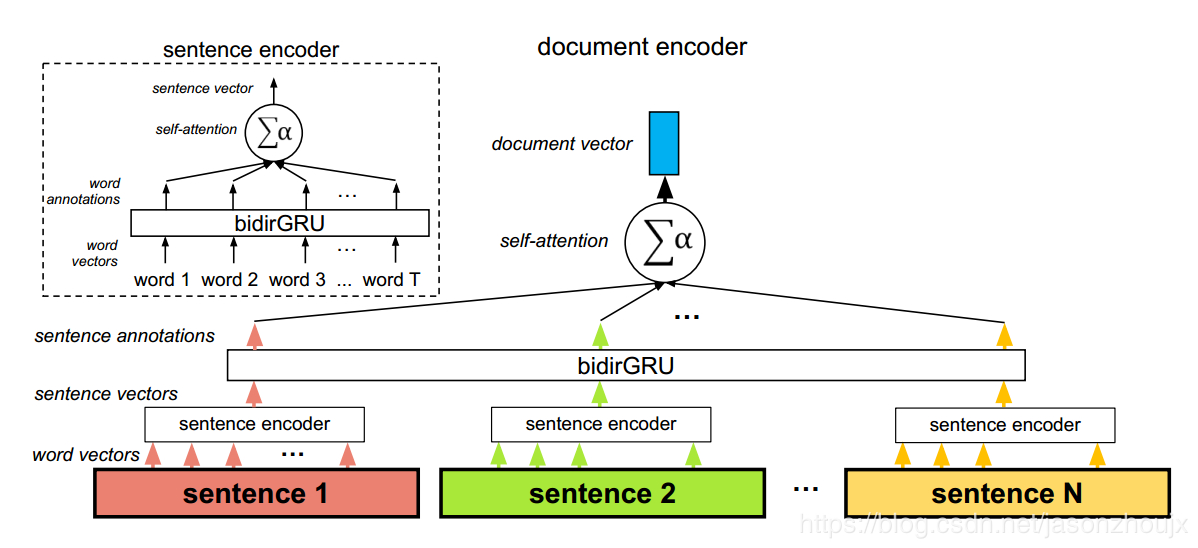
HAN的原理(Hierarchical Attention Networks)
HAN是在“Hierarchical Attention Networks for Document Classification”此文中提出。层级“注意力”网络的网络结构如图所示,网络可以被看作为两部分,第一部分为词“注意”部分,另一部分为句“注意”部分。整个网络通过将一个句子分割为几部分,对于每部分,都使用双向RNN结合“注意力”机制将小句子映射为一个向量,然后对于映射得到的一组序列向量,再通过一层双向RNN结合“注意力”机制实现对文本的分类。
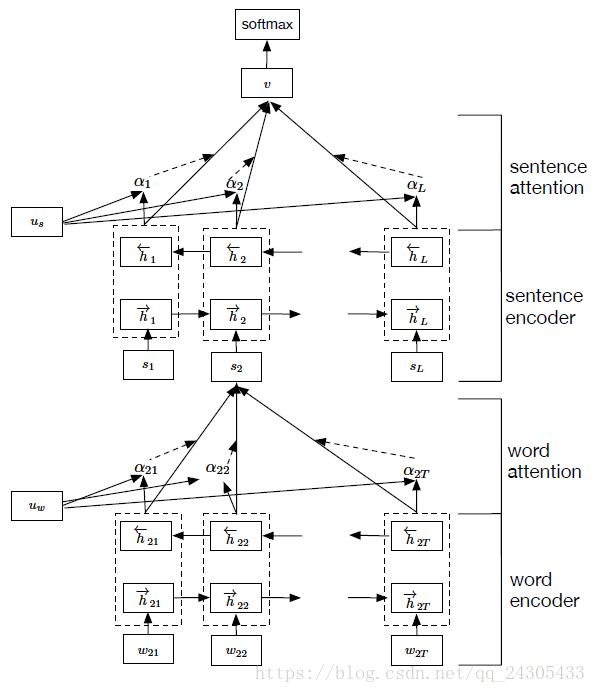
模型主要可以分为四个部分:
- a word sequence encoder,
- a word-level attention layer,
- a sentence encoder
- a sentence-level attention layer.
Word Encoder
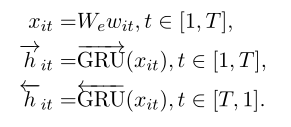
Word Attention
Sentence Encoder
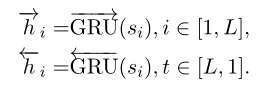
Sentence Attention
最后就是使用最常用的softmax分类器对整个文本进行分类
损失函数为:

