朴素贝叶斯的原理
贝叶斯分类是一类分类算法的总称,这类算法均已贝叶斯定理为基础,故统称为贝叶斯分类。
公式如下:
该公式最大的优点就是可以忽略AB的联合概率直接求其条件概率分布。
因为整个形式化过程只做最原始、最简单的建设:各特征属性是条件独立的:
所以称为“朴素”。
优点:在数据较少的情况下仍然有效,可以处理多类别问题
缺点:对于输入数据的准备方式较为敏感
利用朴素贝叶斯模型进行文本分类
1 | from sklearn import naive_bayes |
1 | def getData(): |
1 | df = getData() |
| SepalLengthCm | SepalWidthCm | PetalLengthCm | PetalWidthCm | target | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0 |
1 | X_train, X_test, y_train, y_test = train_test_split( |
1 | SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm |
1 | model = naive_bayes.GaussianNB() |
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
1 | count = 0 |
贝叶斯准确率: 0.977778
贝叶斯模型得分: 0.978
SVM的原理
定义在特征空间上的间隔最大的线性分类器,可以通过核技巧,变成非线性分类器。
优点:泛化错误率低,计算开销不大,结果易解释
缺点:对参数调节和核函数的选择敏感,原始分类器不加修改仅适用于二分类问题
点到超平面的距离:
找到具有最小间隔的数据点,再对该间隔最大化:
转化后的优目标函数:
引入松弛变量后约束条件变为:
利用SVM模型进行文本分类
1 | from sklearn import svm |
1 | def getData(): |
1 | df = getData() |
1 | model = svm.SVC() |
[ 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 -1 0 0
0 0 0 0 0 0 0 0 1 0 0 -1 1 0 0 0 -1 1 1 0 0]
1 | count = 0 |
SVM准确率: 0.800000
SVM模型得分: 0.800
pLSA、共轭先验分布
LSA(Latent semantic analysis,隐性语义分析)
对词-文档共现矩阵进行 SVD,从而得到词和文档映射到抽象出的 topic 上的向量表示。
LSA 通过将词映射到 topic 上得到 distributional representation(词的分布表示),进而缓解文档检索、文档相似度计算等任务中所面临的同义词(多词一义)问题。
LSA 这种将词映射到 topic 上的向量表示,很难去应对一词多义问题
pLSA(Probabilistic latent semantic analysis,概率隐性语义分析)
pLSA 模型是有向图模型,将主题作为隐变量,构建了一个简单的贝叶斯网络,采用EM算法估计模型参数。相比于 LSA 略显“随意”的 SVD,pLSA 的统计基础更为牢固。
相比于 LDA 模型里涉及先验分布,pLSA 模型相对简单:观测变量为文档 $d_m\in D$ (文档集共 $M$ 篇文档)、词 $w_n\in W$ (设词汇表共有 $V$ 个互不相同的词),隐变量为主题 $z_k\in Z$ (共 $K$ 个主题)。在给定文档集后,我们可以得到一个词-文档共现矩阵,每个元素 $n(d_m,w_n)$ 表示的是词 $w_n$ 在文档 $d_m$ 中的词频。
pLSA 模型也是基于词-文档共现矩阵的,不考虑词序。
pLSA 模型通过以下过程来生成文档(记号里全部省去了对参数的依赖):
- 以概率 $P(d_m)$ 选择一篇文档 $d_m$
- 以概率 $P(z_k|d_m)$ 得到一个主题 $z_k$
- 以概率 $P(w_n|z_k)$ 生成一个词 $w_n$
概率图模型如下所示:
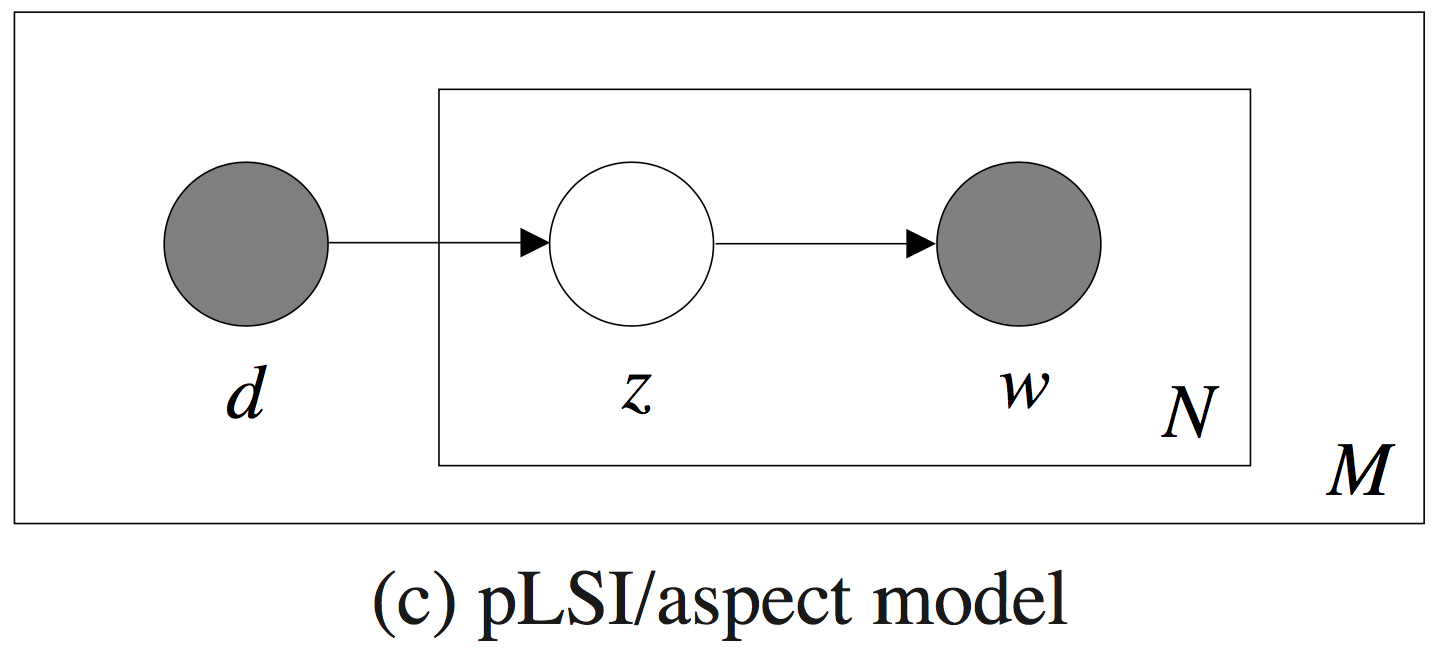
图里面的浅色节点代表不可观测的隐变量,方框是指变量重复,内部方框表示的是文档 $d_m$ 的长度是 $N$,外部方框表示的是文档集共 $M$ 篇文档。pLSA 模型的参数 $\theta$ 显而易见就是:$K×M$ 个 $P(z_k|d_m)$ 、$V×K$ 个 $P(w_n|z_k)$ 。$P(z_k|d_m)$ 表征的是给定文档在各个主题下的分布情况,文档在全部主题上服从多项式分布(共 M 个);$P(w_n|z_k)$ 则表征给定主题的词语分布情况,主题在全部词语上服从多项式分布(共 $K$ 个)。
共轭先验分布
用于计算后验概率的式子:
有时我们将 $p(x|\theta)$ 称为似然函数,先验概率 $pi(\theta)$ 和似然函数的乘积,然后归一化得到后验概率 $p(\theta|x)$。共轭先验的定义为:如果后验概率分布和先验概率分布有相同的形式(如同为指数族分布),则后验概率分布和先验概率分布统称共轭分布。那么先验概率 $\pi(\theta)$ 称为似然函数的共轭先验。
LDA主题模型原理
LDA(Latent Dirichlet allocation,隐狄利克雷分配)
LDA 将模型参数视作随机变量,将多项式分布的共轭先验(也就是 Dirichlet分布)作为参数的先验分布,并使用Gibbs sampling方法对主题进行采样。
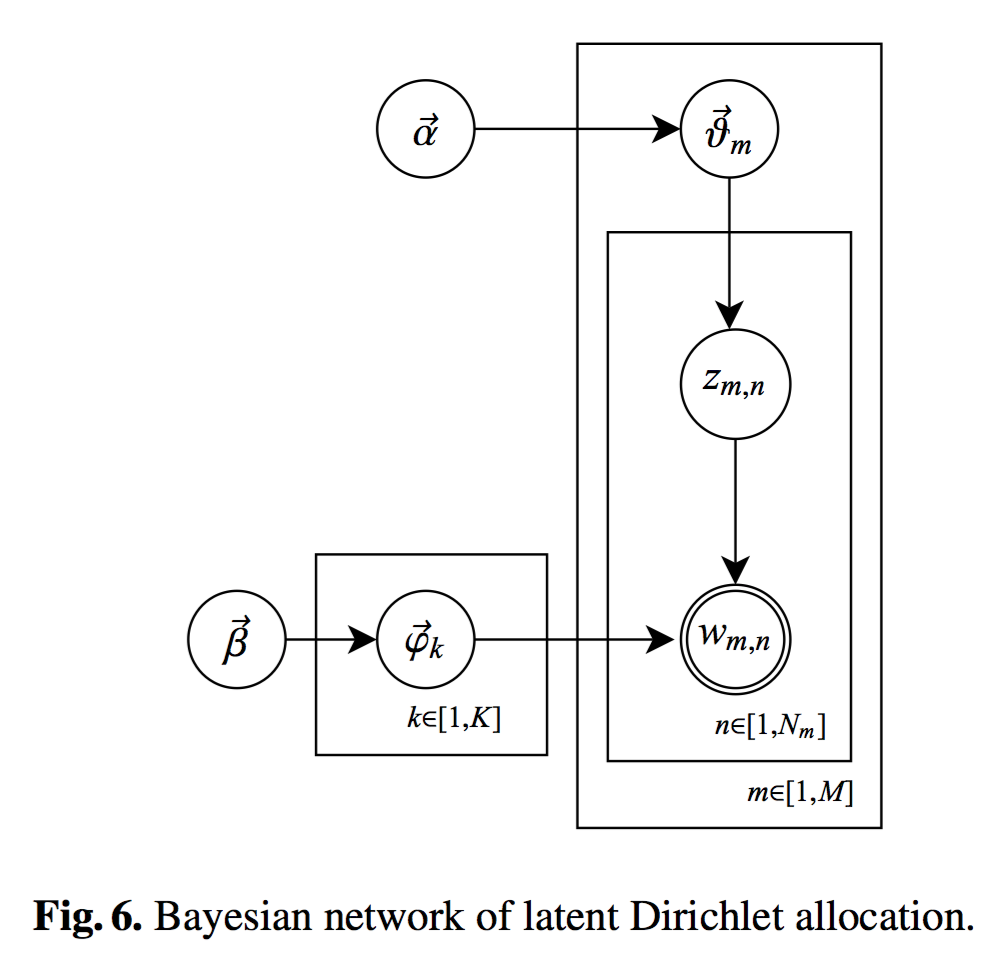
使用LDA生成主题特征,在之前特征的基础上加入主题特征进行文本分类
参考资料
NLP —— 图模型(三)pLSA(Probabilistic latent semantic analysis,概率隐性语义分析)模型
深入浅出讲解LDA主题模型

