TF-IDF原理
Term Frequency-Inverse Document Frequency, 词频-逆文件频率
TF-IDF是一种用于资讯检索与文本挖掘的常用加权技术,一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。
主要思想:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上是:TF * IDF。
- 词频(Term Frequency,TF):某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)
- 逆向文件频率(Inverse Document Frequency,IDF):一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
算法细节:
- 第一步,计算词频 或
- 第二步,计算逆文档频率
需要一个语料库(corpus),用来模拟语言的使用环境 如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。 - 第三步,计算TF-IDF TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比
优点:简单快速,结果比较符合实际情况。
缺点:单纯以”词频”衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。
无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同。
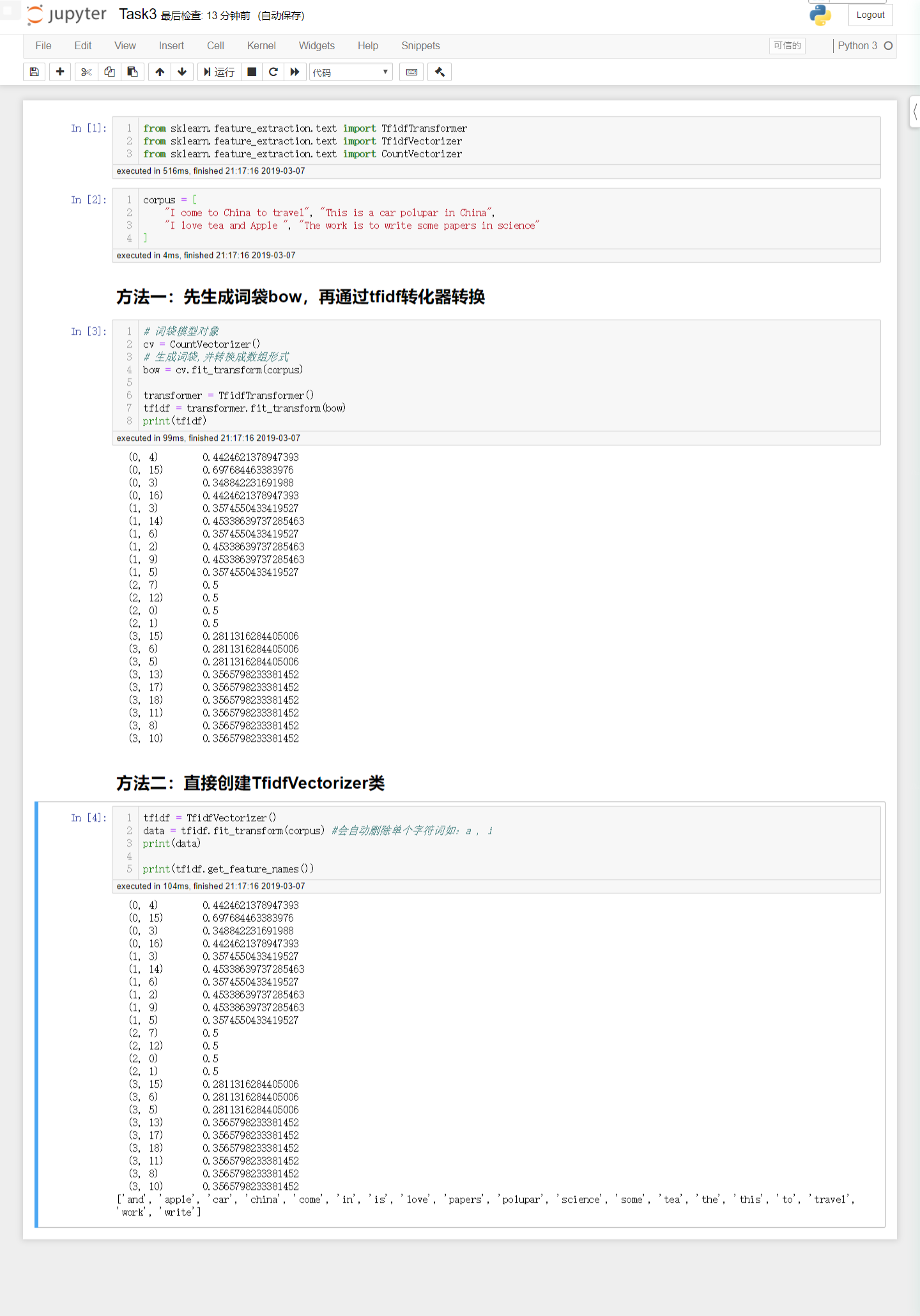
文本矩阵化,使用词袋模型,以TF-IDF特征值为权重
互信息的原理
机器学习相关文献里面,经常会用到点互信息PMI(Pointwise Mutual Information)这个指标来衡量两个事物之间的相关性(比如两个词)。
p(x):单词x在文档中出现的概率
p(y):单词y在文档中出现的概率
p(x,y):单词x,y同时出现在一个文档的概率
由公式可知:
当x,y相互独立时,PMI = log1 = 0
当x,y相关性越大,p(x,y)就相比于p(x)p(y)越大,即PMI值越大。
点互信息PMI其实就是从信息论里面的互信息这个概念里面衍生出来的。
互信息:
互信息衡量的是两个随机变量之间的相关性,即一个随机变量中包含的关于另一个随机变量的信息量。
可以看出互信息其实就是对X和Y的所有可能的取值情况的点互信息PMI的加权和。
3、python sk-learn工具包求互信息:
1 | from sklearn import metrics as mr |
使用第二步生成的特征矩阵,利用互信息进行特征筛选
1 | from sklearn import datasets |
[0.53921701 0.24858998 0.98330489 0.992654 ]

